What is text mining ?
According to definition of wikipedia Text mining, also referred to as text data mining, roughly equivalent to text analytics, is the process of deriving high-quality information from text.
According to Ted Kwartler instructor on Data Camp text mining is the process of distilling actionable insights from text.
Workflow of text mining :
Text mining workflow can be broken into six different components and each and every step is very important.
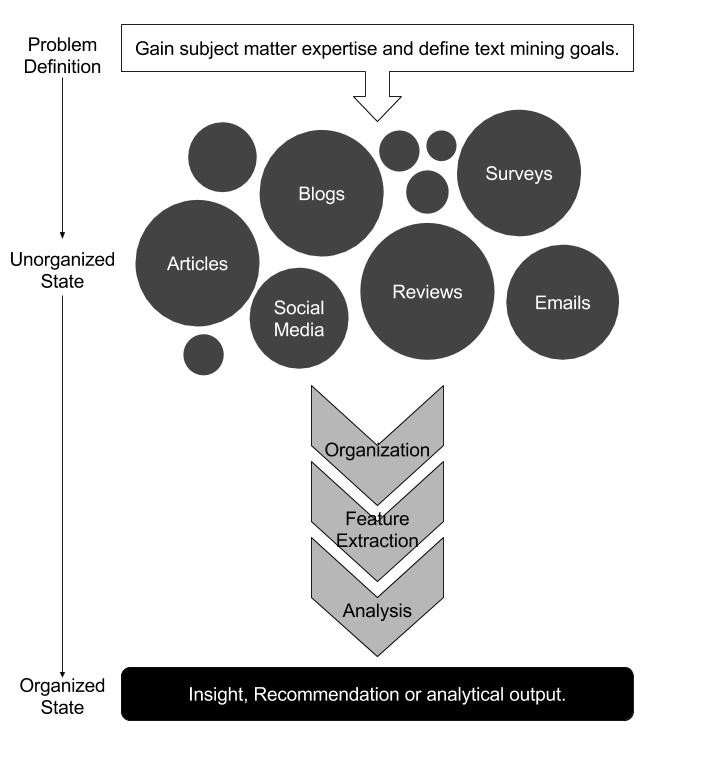
These are :
- Problem definition & Specific goals
- Identity text to be collected
- Text Organization
- Feature Extraction
- Analysis
- Reach a insights
There are two approaches for text mining :
-
- Semantic Parsing
- Bag of Words
Bag of Words
represents a way to count terms, or n-gram, a cross a collection of documents.
Consider the following example in which we are storing some text inside a text variable like this
text <- "Text mining usually involves the process of structuring the input text. The overarching goal is, essentially, to turn text into data for analysis, via application of natural language processing (NLP) and analytical methods."
Count number of words of Indian Prime Minister Modi entire speeches.
If I am saying count number of words in the above sentence then it may be a little bit painful for you but you can do it.But if I am saying count number of words of Prime Minister Narendra Modi entire speech.Then it became a tough task for us.
But we don’t worry about this because R contains alternate for this problem in for qdap package.
qdap package contains many functions that help us to solve various problems of text mining.
freq_terms() -> Find the most frequently occurring terms in a text vector.
Synatx : freq_terms(text,top)
Arguments
text : The text variable.
Top: The top number of terms to show.
Example: Find out 4 most frequent terms in the above text.
library("qdap")
freq_terms(text,4)
Loading text
Text mining begins with loading some data or text into some folder or file.It is known as corpus I will explain in more detail about corpus latter.In this case for loading data we are considering csv files and as we know in R for loading csv file we are simply using read.csv() function.
Note : By default read.csv() treats character strings as factor levels like Male/Female. To prevent this from happening, it’s very important to use the argument stringsAsFactors = FALSE.
Along with qdap package we are using one more package for text mining that is known as tm. tm package is basically used for text mining.
The main structure for managing document in tm is so-called Corpus, that represents a collection of text document.
Corpus : collection of Documents.
Corpus classified into two categories :
- The permanent corpus (Pcorpus)
- The volatile corpus(Vcorpus)
PCorpus : Documents i.e Corpus are physically stored outside R Object.Such type of R objects are basically only pointers to external structure.
Vcorpus : Corpora (R objects) that are fully loaded in memory is known as Vcorpus or volatile corpus as name suggest these are volatile and once the Corpora that mean R Object is destroyed then at that our whole corpus will also gone.
Note : When we compare PCorpus to Vcorpus in case of PCorpus Corpus is not affected, If R Object is destroyed as in Vcorpus happened.
How to construct a Volatile Corpus ?
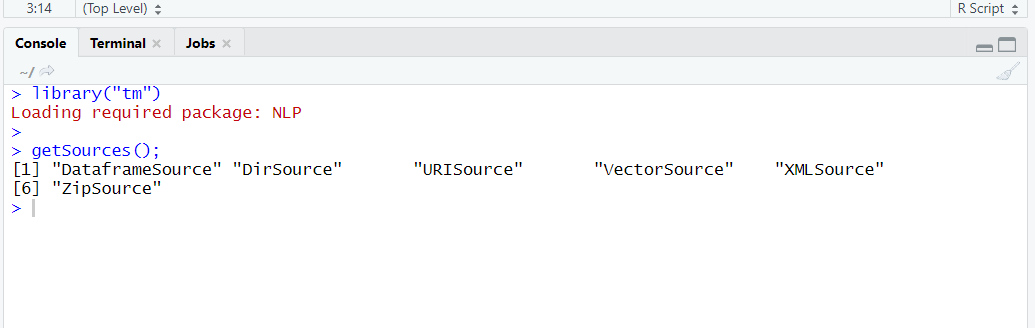
In Order to create a VCorpus using tm package we need to pass a “source” Object as a parameter to the Vcorpus method. We can find these sources using getSources() method.
library("tm")
getSources();
Output
Short Description about these sources :
DirSource : Which is designed for only directories on a file system.
VectorSource: Can be able to handle only vectors and it is only for character vectors.
DataframeSource : Used for handling data frame csv like structure.
In this post I am sharing an Example of VectorSource and in next post I will cover DirSource and DataframeSouce briefly.
Example :
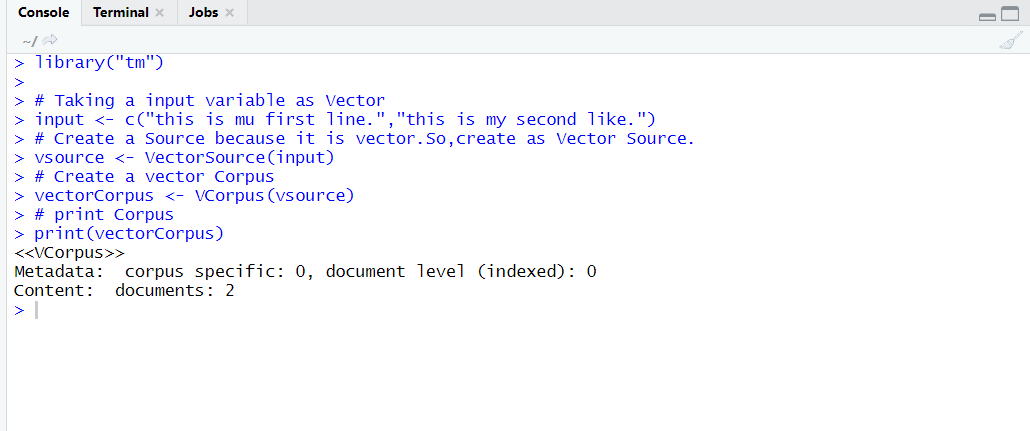
library("tm")
# Taking a input variable as Vector
input <- c("this is mu first line.","this is my second like.")
# Create a Source because it is vector.So,create as Vector Source.
vsource <- VectorSource(input)
# Create a vector Corpus
vectorCorpus <- VCorpus(vsource)
# print Corpus
print(vectorCorpus)
Output: