Puppeteer is a Node.js library that allows you to control Chrome browser from JS code. Most things that you can do manually in the browser can be done using Puppeteer. Here are a few examples to get you started:
Most things that we do manually in the browser.Can be done using puppeteer easily.
What we can do?
- Scrap web page
- Automate process on the web
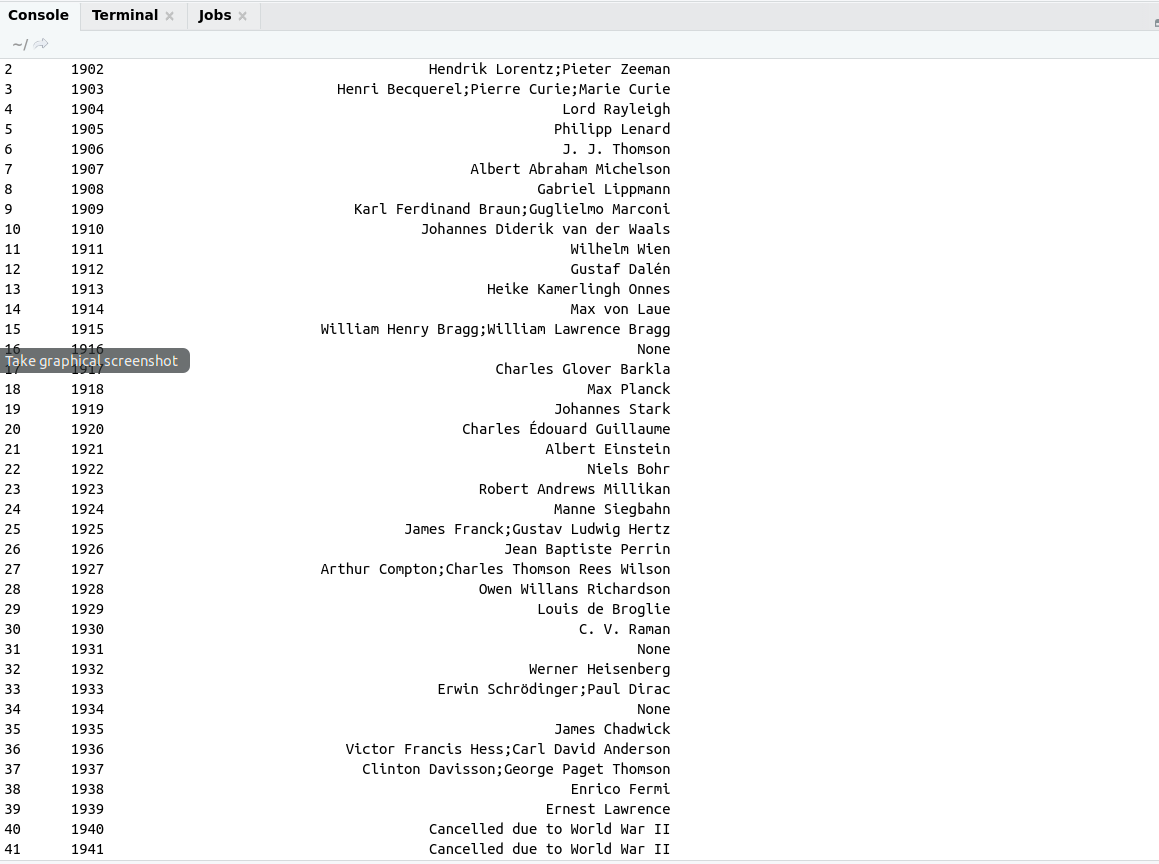
- Take screenshot of web pages
- Generate pdf from HTML
How to start with Puppeteer?
For starting with Puppeteer we have to follow these few steps
-
- Install Puppeteer
- Load Puppeteer module
- Launch Browser
- Headless mode
- Open tab inside Browser
- Open page inside Browser
- Close Browser
Install Puppeteer
Installing Puppeteer
Load Puppeteer package
In node.js we load the package using require like
const puppeteer = require('puppeteer');
Launch browser
To launch browser with puppeteer we have to use launch() method
(async () => {
const browser = await puppeteer.launch();
})();
We can also write this
puppeteer.launch().then(async browser =>{
});
Headless mode
Puppeteer launches chromium in headless mode.
By default puppeteer launch in headless mode i.e
{headless:true}
This means when we will run the application our browser will not be opened.
But during the process, we can make our browser open and for this, we have to make
Open tab inside Browser
nextPage() method on browser object to get page Object.
const puppeteer = require('puppeteer');
(async () => {
const browser=await puppeteer.launch();
const page=await browser.newPage();
});
Open page inside Browser
page.goto() method used for open particular page inside opened browser
const puppeteer = require('puppeteer');
(async () => {
const browser=await puppeteer.launch();
const page=await browser.newPage();
await page.goto("https://google.com/");
});
Close Browser
Textbrowser.close() Used for close browser Once task has been completed.
await browser.close();
Example :
Here we are opening google.com using puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://google.com/');
await browser.close();
})();
For running application we use command
During the above process, the browser will be opened and closed and we can’t be able to track the process. Because in this case {headelss: true}
If we want to track process then, in that case, we have to take {headelss: false}. In this case, the browser will be visualized and we can be able to see steps and debug our code if required.
const puppeteer = require('puppeteer');
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({headless:false});
const page = await browser.newPage();
await page.goto('https://google.com/');
await browser.close();
})();
Here we are not dealing with all methods of puppeteer because it has been already done on its official site https://pptr.dev/.
What are we doing here?
Our main purpose is to take an idea of puppeteer and making projects so that we have a good hand on puppeteer.
For this purpose, we need to familiar with some important classes and modules of puppeteer and that we will cover here.
Classes of puppeteer module
These are some important classes of puppeteer module
page method
page class is a very important class in the puppeteer module. Without creating page Object we can’t be able to open a page on chrome browser.
Some methods of page() class
| Method | Way to write | Description |
|---|---|---|
| $(selector) | await page.$(‘.common’) | querySelector on the page. |
| $$(selector) | await page.$$(‘#intro’) | querySelectorAll on the page. |
| goto(url) | await page.goto(‘url’) | a Used for open a specified url. |
| content() | await page.content() | Get an HTML source of the page. |
| click(selector) | await page.click(‘button#submit’) | a Mouse click event on the element pass as a parameter. |
| hover(selector) | await page.hover(‘input[name=”user”]’) | Hover particular elemet. |
| reload() | await page.reload() | a Reload a page. |
| pdf() | await page.pdf({path:’file.pdf’}) | Generate pdf for open url page. |
| screenshot() | await page.screenshot({path:file.png’}) | Take screenshot of page and save as png format. |