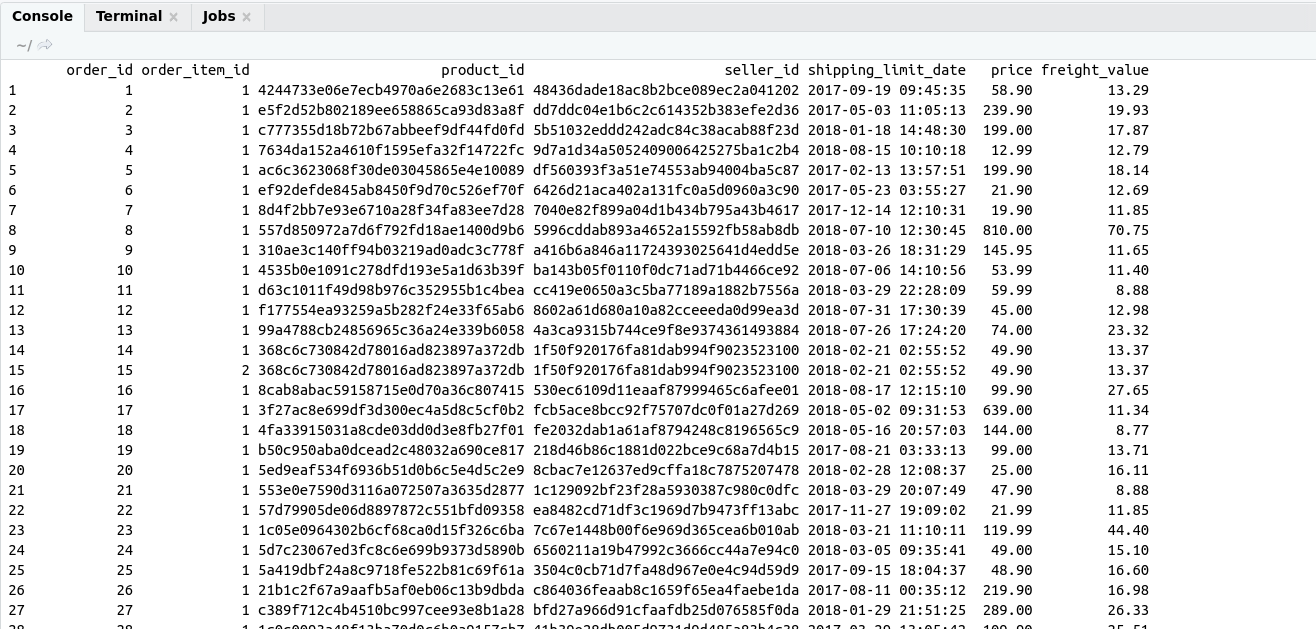
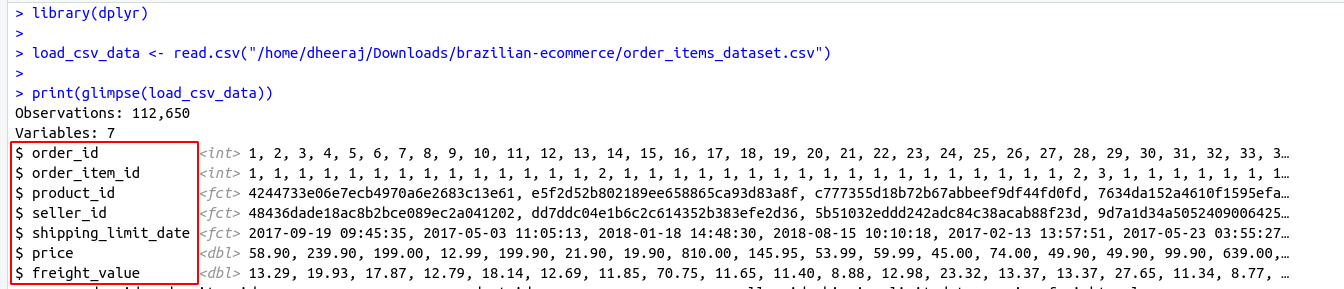
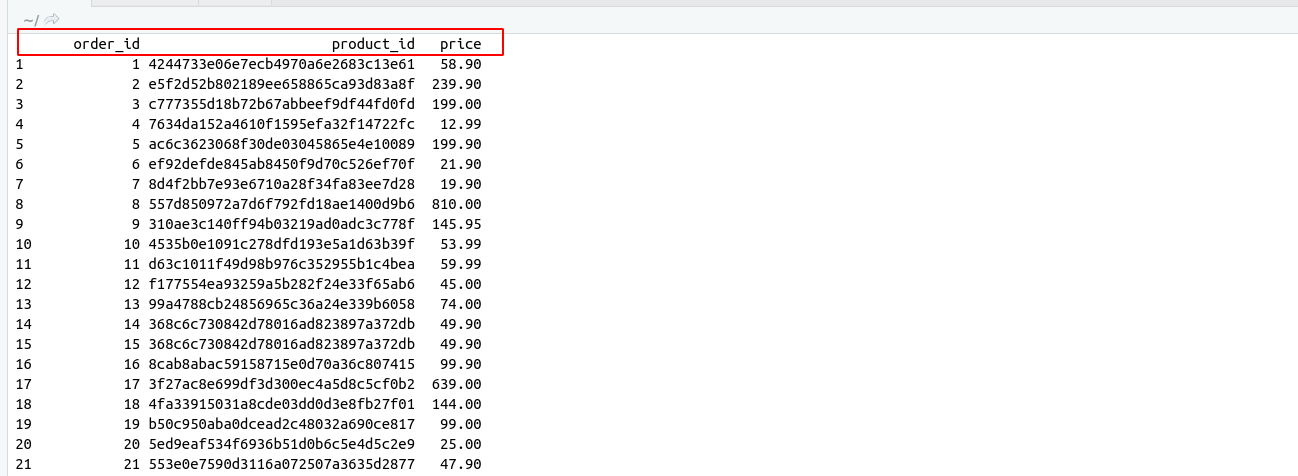
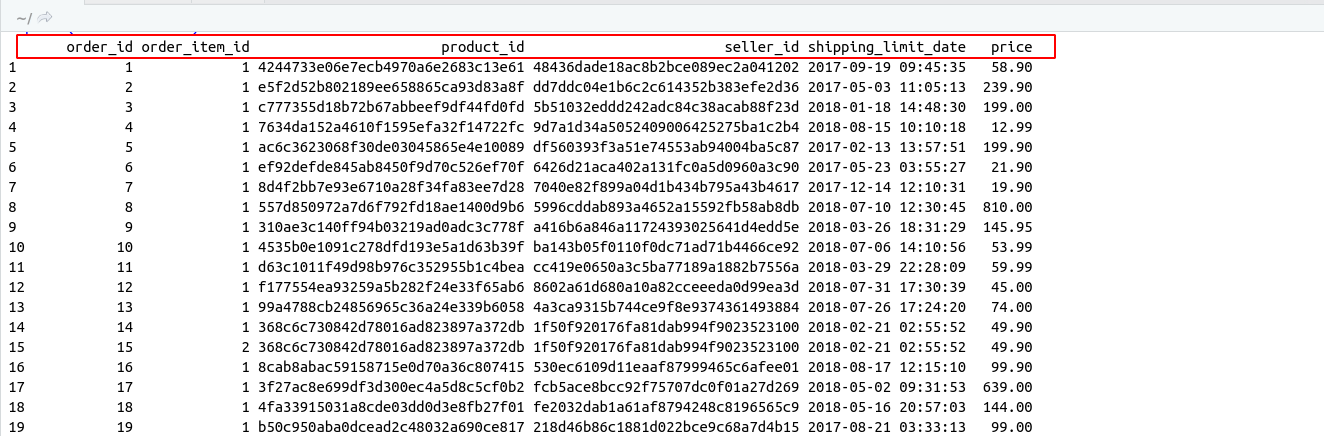
Introduction to SQL :
SQL stands for Structural Query Language.
According to the survey of StackOverflow SQL always remains in the top 5 programming language in the world.
It means you are learning one of the most popular language in the world.
Operation in SQL :
Create Operation :
Create Operation is most basic operation in SQL.
Create operation is used for multiple purposes like creating a table, creating schema, etc.
For performing a Create Operation, we use Create Command with some keyword as
CREATE SCHEMA :
CREATE SCHEMA command is used for creating schema in SQL
Syntax:
/**
CREATE SCHEMA
*/
CREATE SCHEMA shema_name;
Example:
/**
CREATE SCHEMA
*/
CREATE SCHEMA e_commerce_db;
CREATE TABLE :
Used for Creating table
Syntax :
/**
CREATE SCHEMA
*/
CREATE TABLE table_name (column_name1 data type key order_detailsconstraints,column_name1 data type key constraints … column_namen data type key constraints)
Example:
/**
CREATE TABLE
*/
Create table professionals_records(
id int primary key not null AUTO_INCREMENT,
name varchar (100),
mobile varchar(10),
email varchar(200),
city varchar(100),
occupation varchar(200),
designation varchar(100),
salary float
)
CREATE VIEW :
After creating table SELECT command is used for view data inside table (latter discussed about SELECT command). But in the case of SQL, we don’t show the same data for all users. So, in that case, we have to CREATE VIEW.
Syntax :
/**
CREATE SCHEMA
*/
CREATE VIEW AS view_name( Query for view)
Note: We will explain the Example of View latter in the same post.
shown below in the table
Create Operation Summary
| Create command with keyword |
Description |
Syntax |
Example |
| CREATE SCHEMA |
For creating Schema in Database |
CREATE SCHEMA schema_name |
CREATE SCHEMA e_commerce_db |
| CREATE TABLE |
For creating table in Database |
CREATE TABLE table_name(column_name data type key constraints , …) |
CREATE TABLE order_details(id int primary key, name varchar(25) ) |
| CREATE VIEW |
Used for Creating a view in Database |
CREATE VIEW AS view_name (query for creating a view) |
CREATE VIEW AS view_name(SELECT name FROM order_details) |
order_details
Insert Operation
For Inserting rows inside a table we use insert command.
There are two different ways for Inserting rows inside the table :
- order_detailsInserting a single row inside a table
- Inserting multiple rows inside a table
Inserting a single row inside a table :
Syntax:
# comment line
INSERT INTO TABLE table_name(column1,column2,column3 ... , columnN) VALUES(value1,value2,value3 ..., valueN)
Example:
order_details
# Insert Single line
INSERT INTO professionals_records (id,name,mobile,email,city,occupation,designation,salary)
values (1,'Nitin verma','7739042930','nverma@gmail.com','Jaipur','Engineer','Manager',100000)
Inserting multiple rows inside a table :
Syntax:
order_details
# comment line
INSERT INTO TABLE table_name(column1,column2,column3 ... , columnN)
VALUES(value1,value2,value3 ..., valueN),
(value1,value2,value3 ..., valueN),
(value1,value2,value3 ..., valueN)
.
.
.
(value1,value2,value3 ..., valueN)
Example
# Insert Multiple lines
INSERT INTO professionals_records (id,name,mobile,email,city,occupation,designation,salary)
values
(1,'Nitin Verma,'7739042930','nverma@gmail.com','Jaipur','Engineer','Manager',100000),
(2,'Mukesh Sharma','9939042932','msharma@gmail.com','Jaipur','Engineer','Software Developer',50000),
(3,'Nimesh Mehra','8965721230','rmehra@gmail.com','Jaipur','Engineer','Software Developer',60000)order_details
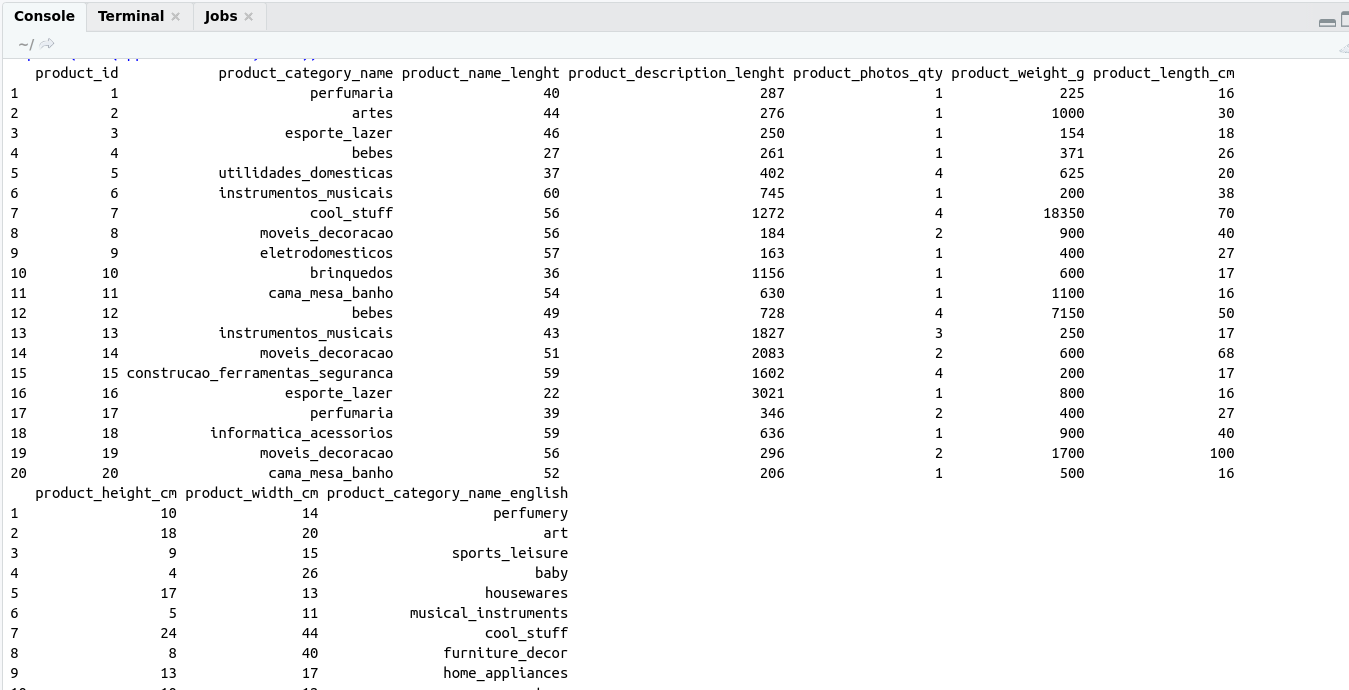
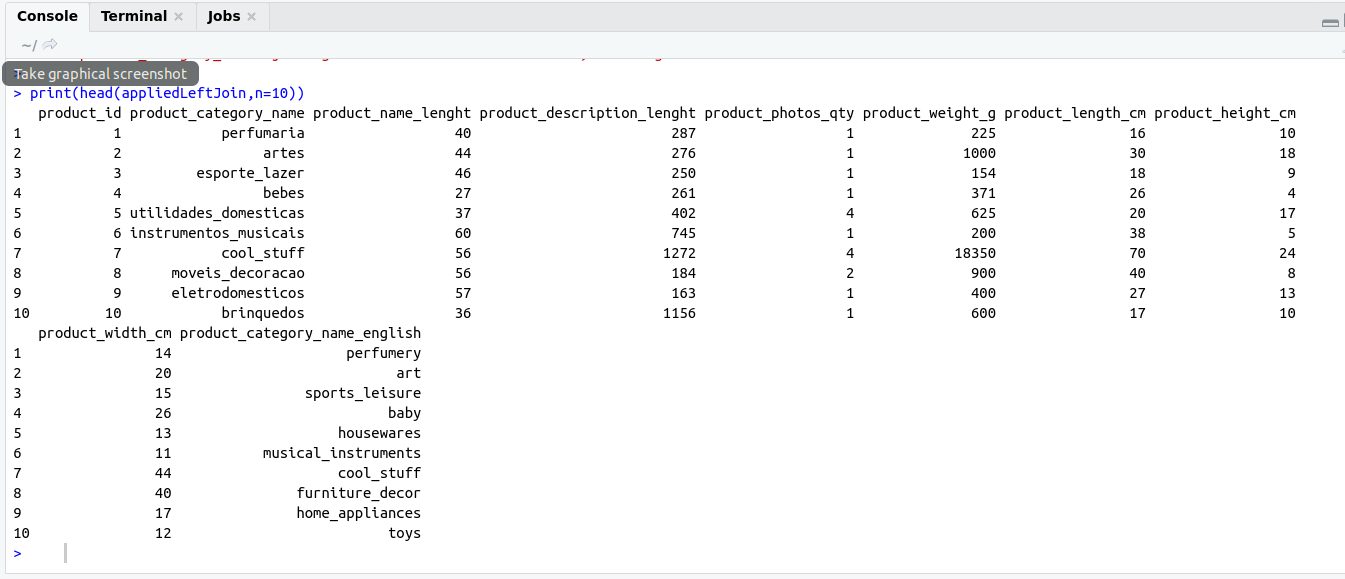
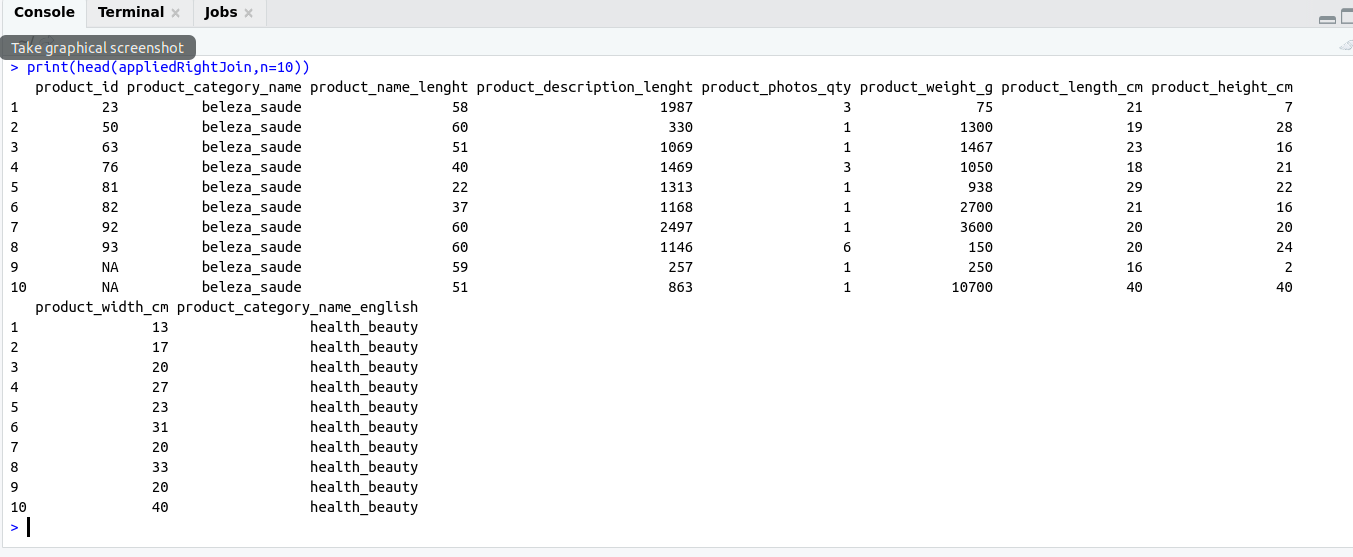
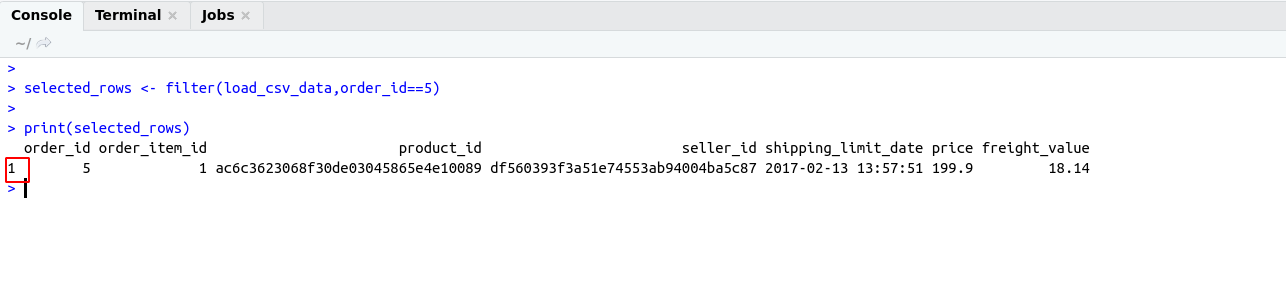
SELECT Operation:
SELECT Statement return result set of records from one or more tables.
Syntax:
# comment line
SELECT * FROM table_name
Note : * denotes all column
Example:
# Select query
SELECT * FROM professionals_records
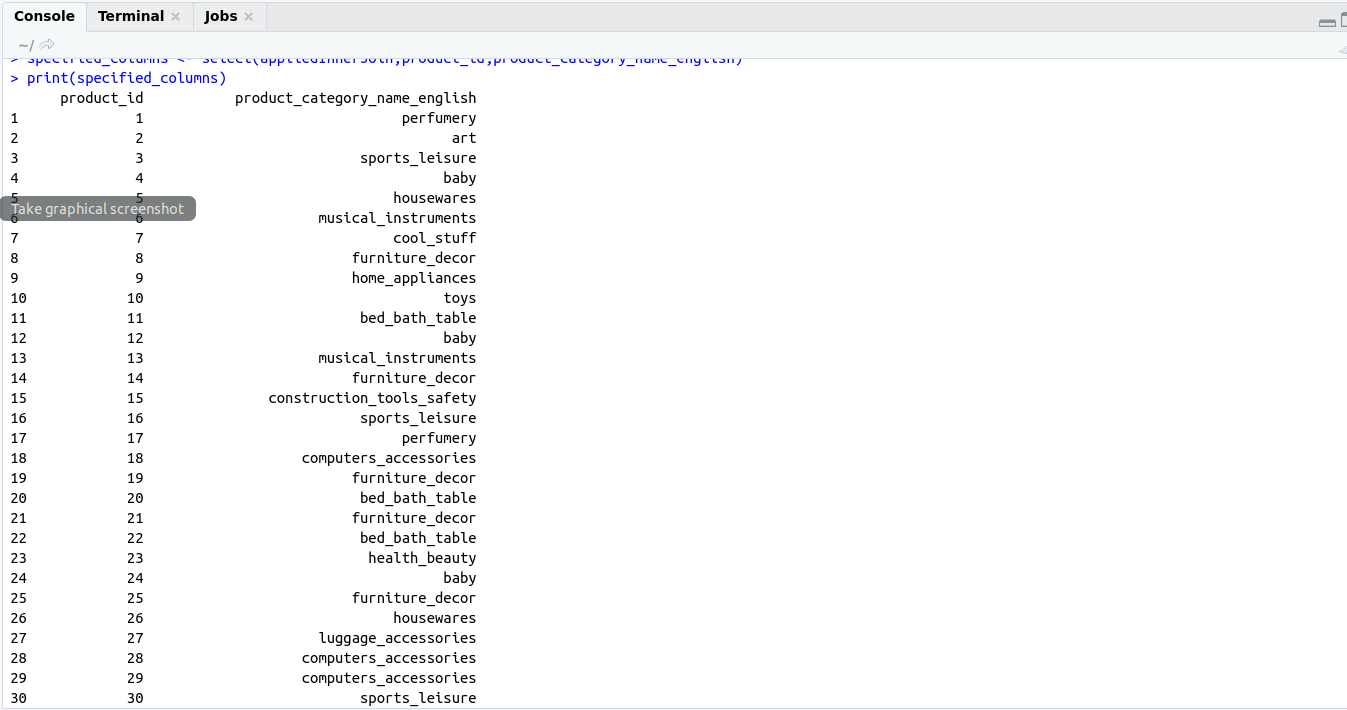
we can also specify specific columns also for extracting a particular column.
Syntax:
# comment line
SELECT column1, column2 ... columnN FROM table_name
Example:
# Select query
SELECT name,mobile,email,city,occupation FROM professionals_records;
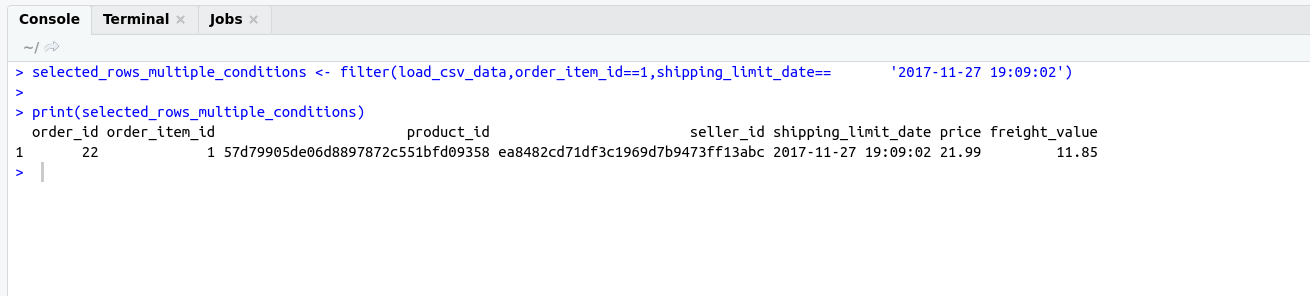
WHERE clause :
It is the most important keyword for SELECT Operation.
It is basically used for filtering data from SQL tables.
Syntax:
# comment line
SELECT * FROM table_name WHERE
Example :
# comment line
SELECT * FROM professionals_records WHERE id=3;
Note: WHERE clause is not only used SELECT statement but also it is also used with UPDATE, DELETE statement.
LIMIT keyword
It is used for limiting how many number of rows that we want to extract.
Syntax :
# comment line
LIMIT number_of_rows;
Example:
order_details
# comment line
SELECT * FROM professionals_records LIMIT 2;
In the above example it will extract only 2 rows from professionals_records table.
Aggregate Function :
Aggregate function basically used for apply a calculation on a column.
It is also used for filtering some value on the basis of some calculations.
Types of Aggregate Function
Note: AVG, SUM, MIN are applied to numerical values. So before applying these functions on a particular column make sure that the column contains numerical values or not.
| Aggregate Function |
Description |
Example |
| AVG() |
Calculate average of a particular column |
SELECT avg(salary) FROM professionals_records; |
| SUM() |
Calculate sum of selected column |
SELECT sum(salary) FROM professionals_records; |
| COUNT() |
Count number of records (rows) |
SELECT count (*) FROM professionals_records;order_details |
| MIN() |
Return minimum value on applied column |
SELECT MIN(salary) FROM professionals_records; |
| MAX() |
Return maximum value of applied column |
SELECT MAX(salary) FROM professionals_records; |
UPDATE Operation:
Used for updating records inside table.
For changing rows data inside a table we use UPDATE command.order_details
Syntax :
# comment line
UPDATE TABLE table_name set column_name=;
Example :
# comment line
UPDATE TABLE professionals_records SET salary=25000
Just wait from the above query all the values of the salary of all employees will be interchanged with 25000.
And we obviously don’t want to do so.
How do we avoid making such type of mistake?
For avoiding such types of mistakes, we will use WHERE Clause.
Syntax:
# comment line
UPDATE TABLE table_name SET column_name= WHERE ;
Example:
order_details
# comment line
UPDATE TABLE professionals_records SET salary=25000 WHERE id=1
Above query update salary=25000 of which id is 1.
DELETION Operation :
order_detailsDeletion Operation is done for deleting records from Database.
For deleting records from the Database table we use Delete Statement.
Syntax:
# comment line
DELETE TABLE table_name
Example:
order_details
# comment line
DELETE TABLE professionals_records
It will delete all records from the professionals_records table.
For deleting particular records, we will have to use WHERE clause as shown below.
DELETE Statement with WHERE Clause
order_detailsorder_detailsSyntax :
# comment line
DELETE TABLE table_name WHERE
Example:
# comment line
DELETE TABLE professionals_records WHERE id=25;
Delete records only for which id is 25.