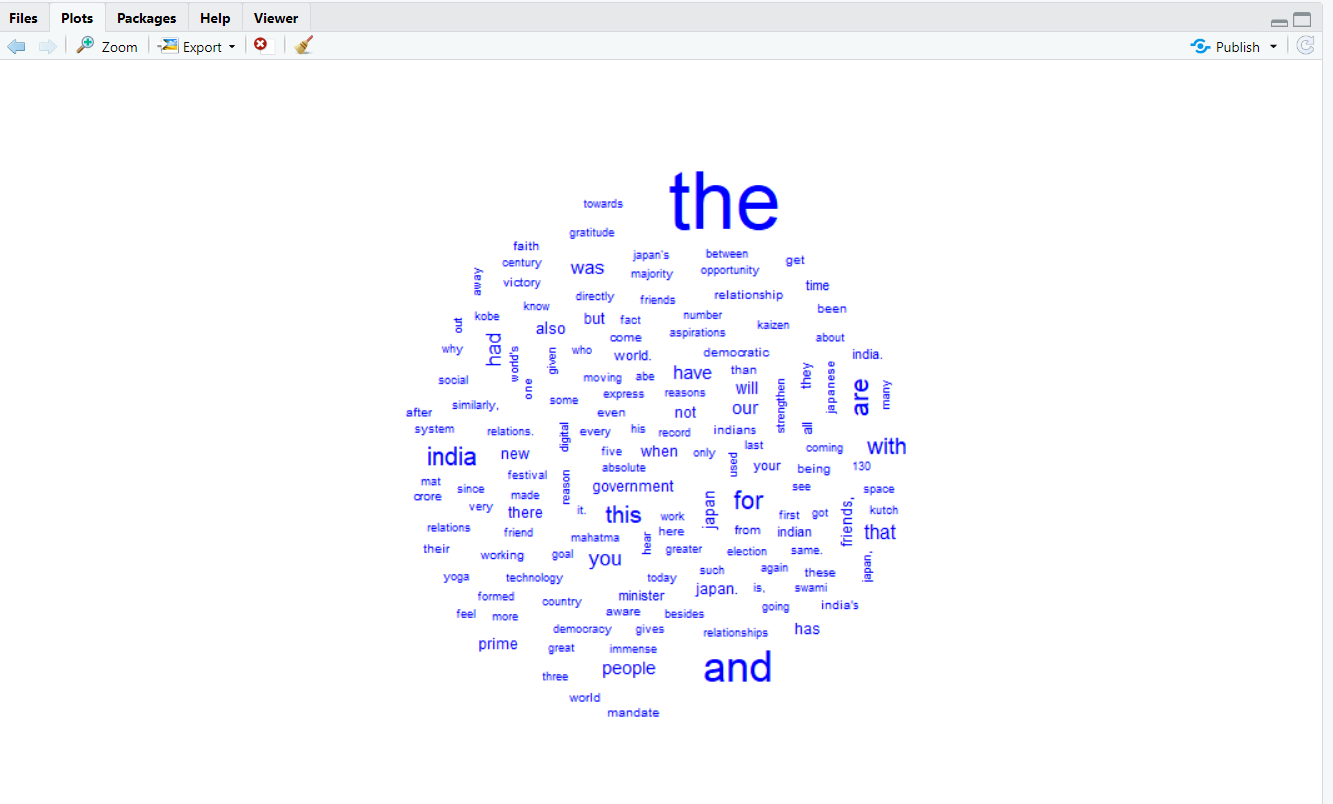
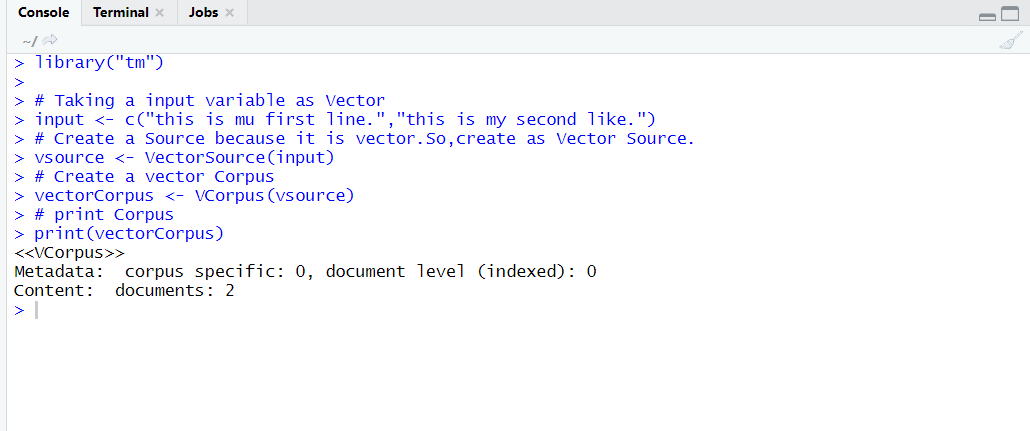
In previous post we had discussed about basic of text mining in R then after that we had little bit talked about Corpus and its types i.e.
- PCorpus
- VCorpus
Then in case of VCorpus we understood it’s Sources like VectorSource, DirSource and DataFreameSource we had already explained VectorSource with an Example in this post we are continuing with VCorpus with it’s two remaining sources i.e. DirSource and DataframeSource with example.
DirSource : It is basically designed for directories on a file system.
So for further explaining about DirSource we will take a folder which contained some text file I have already created a folder which contains different speeches of Indian Prime Minister Modi I will also share link of this folder so that you can be able to easily download file and practice on it.
Example:
#import tm library
library('tm')
#take file
text <- file.path("text_speeches")
dirSourceCorpus <- VCorpus(DirSource(text))
print(dirSourceCorpus)
DataframeSource : Used for handling data frame csv like structure in this case we are creating our own dataframe example.
Example :
#import tm library
library('tm')
# Create a Dataframe example
example_txt <- data.frame(
doc_id=c(1,2,3),
text= c("example_text","Text analysis provides insights","qdap and tm are used in text mining"),
author=c("Author1","Author2","Author3"),
date=c("1514953399","1514953399","1514780598")
)
# Convert DataframeSource frome a example_txt
df_source <- DataframeSource(example_txt)
#Convert df_source to Voletile corpus
df_corpus <- VCorpus(df_source)
#print Voletile Corpus
print(df_corpus)
OutPut :

Some Important functions of TM
| TM Function |
Description |
| tolower() |
Make all content in lower case |
| removePunctuation() |
Remove Punctuations like period exclamatory |
| removeNumbers() |
Remove Numbers i.e basically use for finding pure text |
| stripWhiteSpace() |
Removing tabs and extra spaces |
| removeWords() |
Removing specific word i.e. defined by Data scientist during process |
Now it’s time go for example and understand concept in practical way
#import tm library
library('tm')
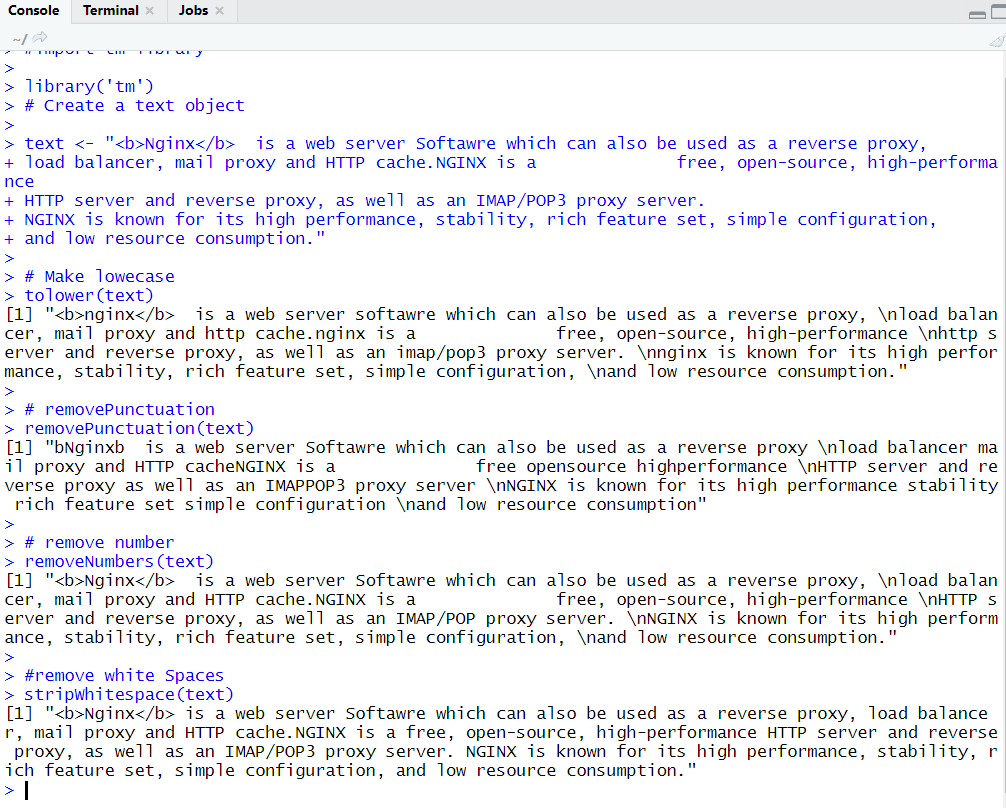
# Create a text object
text <- "Nginx is a web server Softawre which can also be used as a reverse proxy,
load balancer, mail proxy and HTTP cache.NGINX is a free, open-source, high-performance
HTTP server and reverse proxy, as well as an IMAP/POP3 proxy server.
NGINX is known for its high performance, stability, rich feature set, simple configuration,
and low resource consumption."
# Make lowecase
tolower(text)
# removePunctuation
removePunctuation(text)
# remove number
removeNumbers(text)
#remove white Spaces
stripWhitespace(text)
Output :
Like tm package qdap is also very important package for text mining it also contains some important functions that play a vital role during mining
Some of qdap packages are listed here
| QDAP Function |
Description |
| bracketX() |
Remove all contents within bracket |
| replace_number() |
Replace numbers with their equivalent words like ( 3 becomes three) |
| replace_abbreviation() |
Replace abbreviations with their full text equivalents (e.g. “Er” becomes “Engineer”) |
| replace_contraction() |
Convert contractions back to their base words (e.g. “couldn’t” becomes “could not”) |
| replace_symbol() |
Replace common symbols with their word equivalents (e.g. “$” becomes “dollar”) |
Note : Before go for performing qdap example make sure your should contain Java installed.
#import tm library
library('qdap')
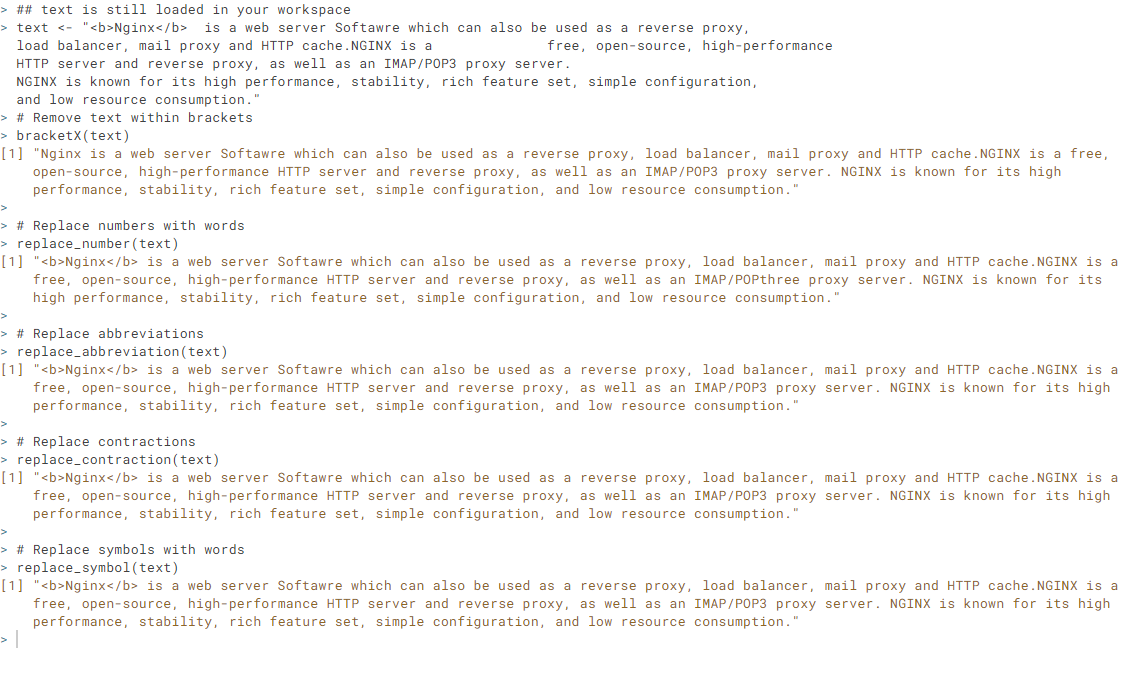
# Create a text object
text <- "Nginx is a web server Softawre which can also be used as a reverse proxy, load balancer, mail proxy and HTTP cache.NGINX is a free, open-source, high-performance HTTP server and reverse proxy, as well as an IMAP/POP3 proxy server.
NGINX is known for its high performance, stability, rich feature set, simple configuration, and low resource consumption."
# Remove text within brackets
bracketX(text)
# Replace numbers with words
replace_number(text)
# Replace abbreviations
replace_abbreviation(text)
# Replace contractions
replace_contraction(text)
# Replace symbols with words
replace_symbol(text)
Output
Stop Words
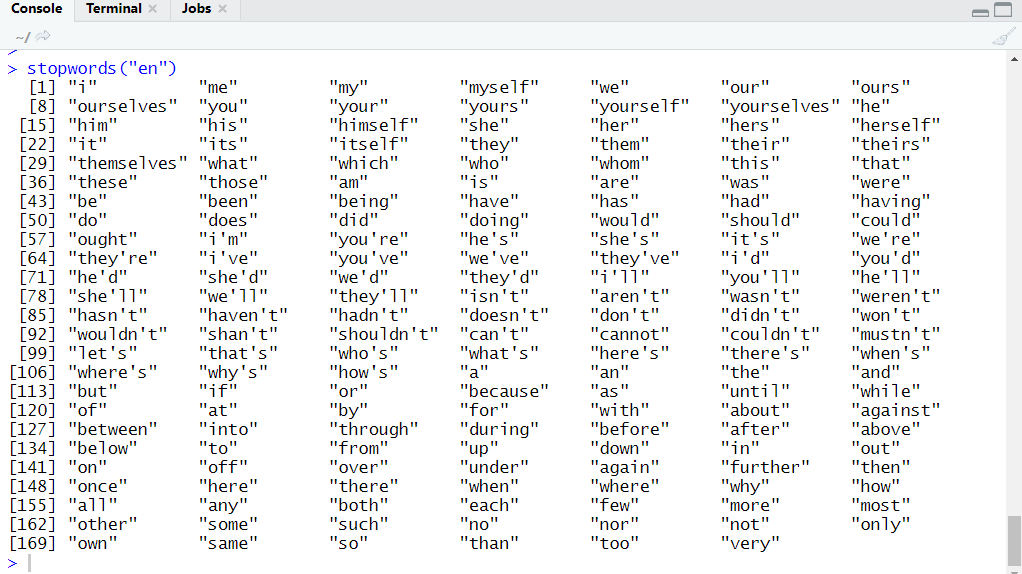
Some words come frequently in text and provide little information such type of words are called stop words.In NLP and text mining stop words becomes barrier for our mining or NLP operation.So,during text mining or NLP we remove stop words from our text.
Words like “the”, “a”, “and” are stop words tm packages contains 174 stop words of english. Although you can stop words according to text that we will discuss during practice session.
# import library
library('tm')
# call stopwords function
stopwords("en")
OutPut:
We can also add new stop words in the list stop.
Add new stop words
For adding new stop words inside list we use c() function like for adding two words like “myword1” and “myword2”
Then we will write
# import library
library('tm')
# call stopwords function
all_stops <- c("myword1","myword2",stopwords("en"))
# print all stop words
print(all_stops)
OutPut : highlighted words are new stop words
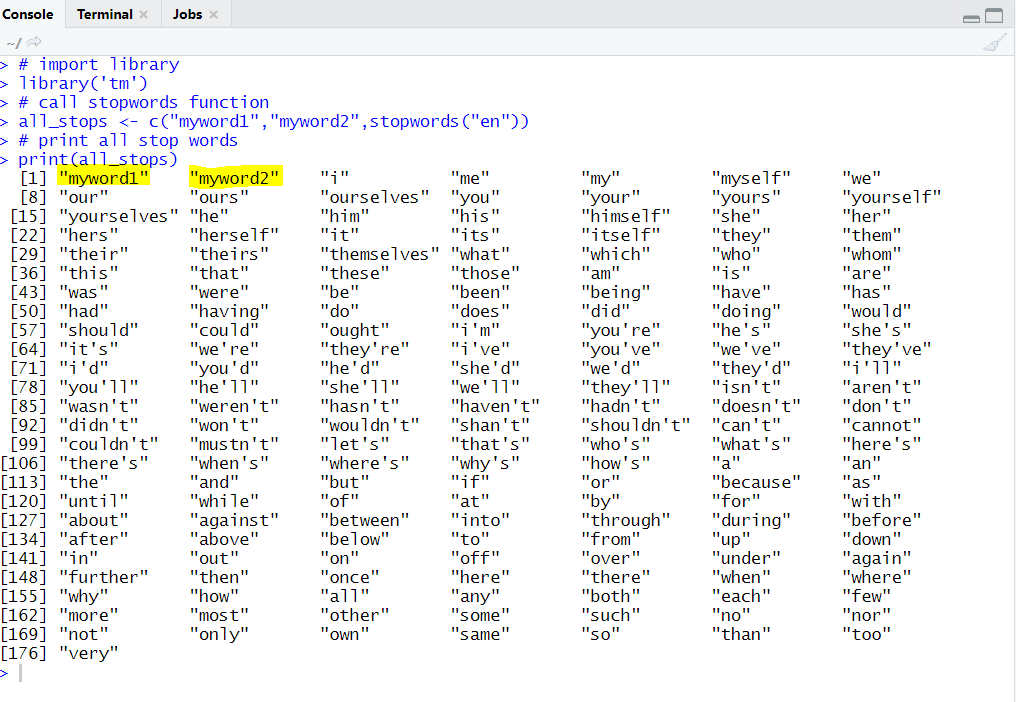
Now it’s time to come when we going to implement stop words concept on real time application.for that purpose we are taking same text example on which we are considering till yet and from that text file we are removing “Nginx” so “Nginx” is our stop words.
#import tm library
library('tm')
# Create a text object
text <- "Nginx is a web server Softawre which can also be used as a reverse proxy,
load balancer, mail proxy and HTTP cache.Nginx is a free, open-source, high-performance
HTTP server and reverse proxy, as well as an IMAP/POP3 proxy server.
Nginx is known for its high performance, stability, rich feature set, simple configuration,
and low resource consumption."
# at first Nginx to stop words
new_stop_words <- c("Nginx",stopwords("en"))
# Remove stop words from text
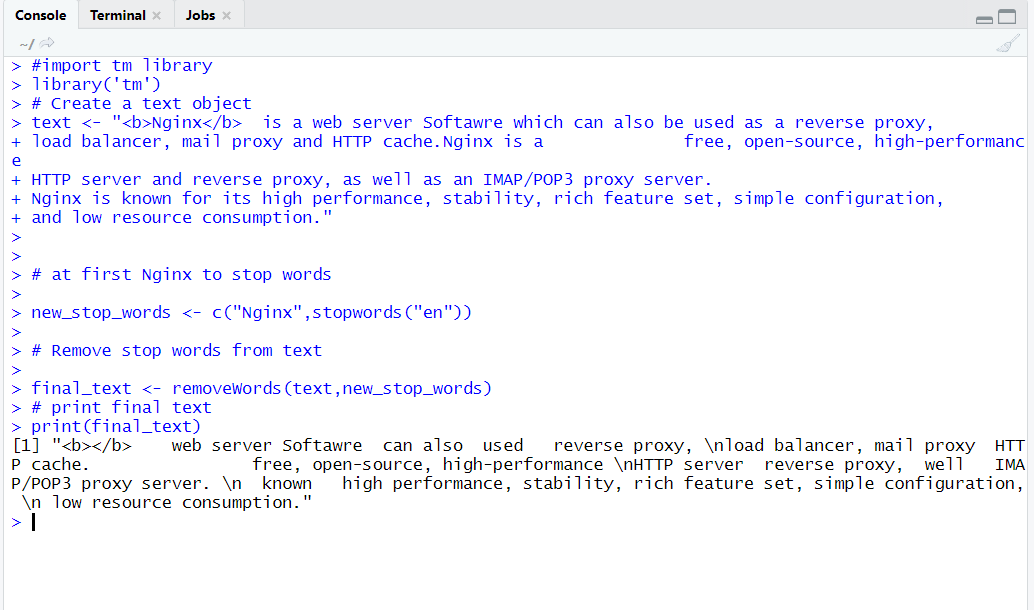
final_text <- removeWords(text,new_stop_words)
# print final text
print(final_text)
Output:
Word Stemming and Stem Completion
Stemming is a pre-processing step in Text-mining application as well as a very common requirement of Natural Language Processing (NLP) functions.
- Stemming is usually done by removing any attached suffixes and prefixes (affixes) from index terms before the actual assignment of term of index.
- Word Stemming reduces words to unify across documents. for example, the stem of “introducing”, “introduction” and “introduces” is “introduce”.
- During the creation of Stemming it may happen sometimes that we construct such word i.e not real then, in that case, we construct a real word and this process is called stem completion.
Important functions that are used for stemming
| TM Stemming function |
Description |
| stemDocument() |
Provides root of word. |
| stemCompletion() |
Reconstruct root word. |
# import library
library('tm')
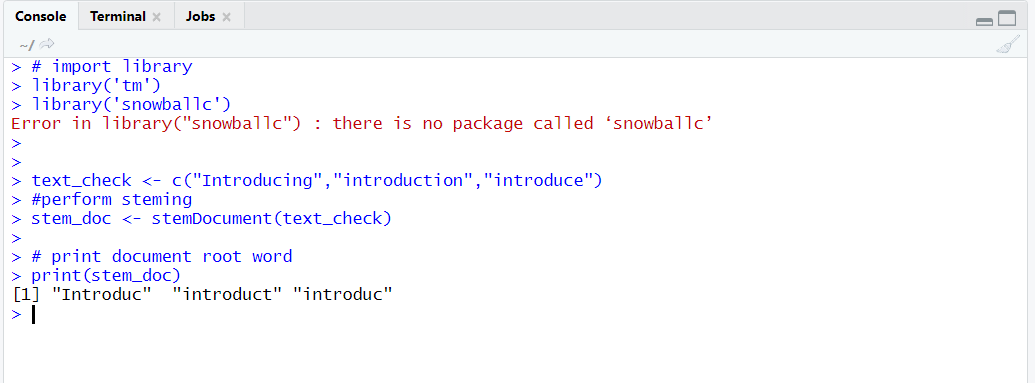
library('snowballc')
text_check <- c("Introducing","introduction","introduce")
#perform stemming
stem_doc <- stemDocument(text_check)
# print document root word
print(stem_doc)
Output:
Reconstruct word in stemming
# import library
library('tm')
library('snowballc')
text_check <- c("Introducing","introduction","introduce")
#perform stemming
stem_doc <- stemDocument(text_check)
# print document root word
print(stem_doc)
# create introduction dictionary
comp_doc <- "Introduce"
# reconstruct root word
stem_doc_reconstruct <- stemCompletion(stem_doc,comp_doc)
#print reconstruct word
print(stem_doc_reconstruct)
OutPut: